大規模言語モデルの推論速度を最大4倍に高速化する新フレームワーク「SPECTRA」を提案
大規模言語モデルの推論速度を最大4倍に高速化する
新フレームワーク「SPECTRA」を提案
【ポイント】
- 既存のLLM(大規模言語モデル)に追加学習や構造変更を一切行わずに、推論速度を大幅に向上させる新たなフレームワークSPECTRAを提案。
- SPECTRAは、SPECTRA-CORE と SPECTRA-RETRIEVAL という2つの革新的なモジュール(単位)で構成され、それぞれがSOTA(最先端手法)を上回る性能を発揮。両者の組み合わせにより、様々なタスクやアーキテクチャにおいて最大 4.08倍の推論速度向上を達成。
- 複数のLLMファミリー、タスク、およびGPU(グラフィック処理装置)環境での大規模実験により、元のLLMと同等の生成品質を維持しながら損失なく高速化できることを示し、実運用において極めて実用的な課題解決方法であることを証明。
| 北陸先端科学技術大学院大学コンピューティング科学研究領域のグエン ミン レ教授らの研究チームは、既存の大規模言語モデル(LLM)に追加学習や構造変更を一切行わずに、推論速度を大幅に高速化する新たな推論加速手法「SPECTRA」を提案しました。 SPECTRAは、LLM自身の予測を活用し、マルチレベルのN-gram(連続するN個の単語や文字列)探索を通じて推論を促進する「SPECTRA-CORE」と、高品質な外部予測候補を選別する「SPECTRA-RETRIEVAL」という2つの革新的なモジュールで構成されており、それぞれ単独でも効果的ですが、組み合わせることで、既存のスペキュレーティブ・デコーディング手法(確定していないことを予想して先にやってみる手法)の制約を克服し、最大4.08倍の推定速度向上を実現します。SPECTRAは、高コストなドラフトモデル(本番モデルより軽量で高速なモデル)の事前学習を必要とせず、また限られた高速化にとどまることもなく、対話からコード生成に至るまで、幅広いタスクにおいて実質的な推論速度向上を実現します。 さらに、出力品質を維持したまま処理の遅延を大幅に減らしたLLMの運用を可能にし、リアルタイムアプリケーションへの応用やAIの実用範囲の拡大に貢献するものです。 |
【研究概要】
現在の大規模言語モデル(LLM)は通常、前に生成したトークン(単語や文字などの最小単位)をもとに一つずつ順番に文章を作る自己回帰的デコーディング(autoregressive decoding)に依存しています。この方式では、トークンを1つずつ逐次生成するため、生成時間がシーケンス長(一度に処理できるテキストの最大の長さ)に比例して線形に増加し、現代GPUの並列処理能力を十分に活かしきれていません。
この非効率性に対処するため、広く研究されているアプローチがスペキュレーティブ・デコーディング(speculative decoding)です。これは、「予測と検証(guess-and-verify)」の戦略に基づいており、小規模なドラフトモデルやLLM自身が複数トークンを先読み予測し、それを元のLLMが並列に検証することで推論の効率を向上させます。しかし、多くの既存手法は追加の学習を必要とするため、計算コストが高く、元のモデル性能に悪影響を及ぼす可能性もあります。
一方、追加学習なしにスペキュレーティブ・デコーディングでトークンを生成するアプローチも模索されています。これにより、LLMの改変や新規モデルの学習が不要となり、既存モデルをそのまま運用(off-the-shelf deployment)できる現実的な選択肢となります。一部の手法では、LLM自身の予測から直接スペキュレーティブ・デコーディングでトークンを生成するための専用技術を使用し、また別の手法では外部情報源を利用して予測の質を高めようとしますが、生成されたトークンの品質が十分でない場合、加速効果は限定的であり、速度向上には限界があります。
本研究では、元のLLMに対して一切の追加学習や構造改変を行わずに、生成速度を向上させる新たなスペキュレーティブ・デコーディング手法「SPECTRA」を提案します。
SPECTRAは、2つの主要構成要素から構成されています(図1参照):
- コアモジュール(SPECTRA-CORE):LLMに対してプラグ・アンド・プレイ(plug-and-play)形式(システムが自動的に導入・設定を行い、利用可能な状態にする形式)で容易に統合可能。
- 任意リトリーバルモジュール(SPECTRA-RETRIEVAL):性能をさらに向上させる追加メカニズム。
SPECTRA-COREは、LLMが予測するトークン分布を活用して高品質な予測(guesses)を生成することで、スペキュレーティブ・デコーディングを改善します。
具体的には、双方向検索を可能にする2種類のマルチレベルN-gram辞書を使用し、動的な長さの予測を生成することで、生成の質と量のバランスを最適化します。さらに、SPECTRAは候補プール(candidate pool)を最適化してN-gram辞書を継続的に更新し、幅広いトークンカバレッジ(プログラムのテスト範囲を測る指標)を確保します。これらの処理システムの更新および予測の検証は、すべて単一のフォワードパス(入力し、出力するまでの流れ)内で効率的に実行されます。
一方、リトリーバルモジュールである SPECTRA-RETRIEVALを併用することで、さらなる高速化が可能となります。既存の外部ソースに依存した予測生成手法は、検索コストが高く、他のスペキュレーティブ・デコーディング技術との統合が困難であるという課題がありますが、SPECTRA-RETRIEVALはこの問題に対処するために、対象LLMによって算出されるパープレキシティスコア(次の単語を予測する際の不確実性の指標)に基づいてコーパス(corpus:大量のテキストデータを集積し、構造化したデータベース)から高品質なコンテンツのみを選択することで検索空間を削減し、SPECTRA-COREとの容易な統合を実現します。これにより、システム全体の効率性を最大化します。
提案手法SPECTRAは、マルチターン対話、コード生成、数学的推論など6種の多様なタスクにおいて、Llama 2、Llama 3、CodeLlamaの3つの主要LLMファミリー(7B〜70Bモデル)を用いた実験により評価されました。その結果、追加学習を必要としない既存のスペキュレーティブ・デコーディング手法を一貫して上回る性能を示し、最大4.08倍の推論速度向上を達成しました。
なお、コードおよびデータはすべて公開されており、今後の研究および応用に活かせる成果となっています。
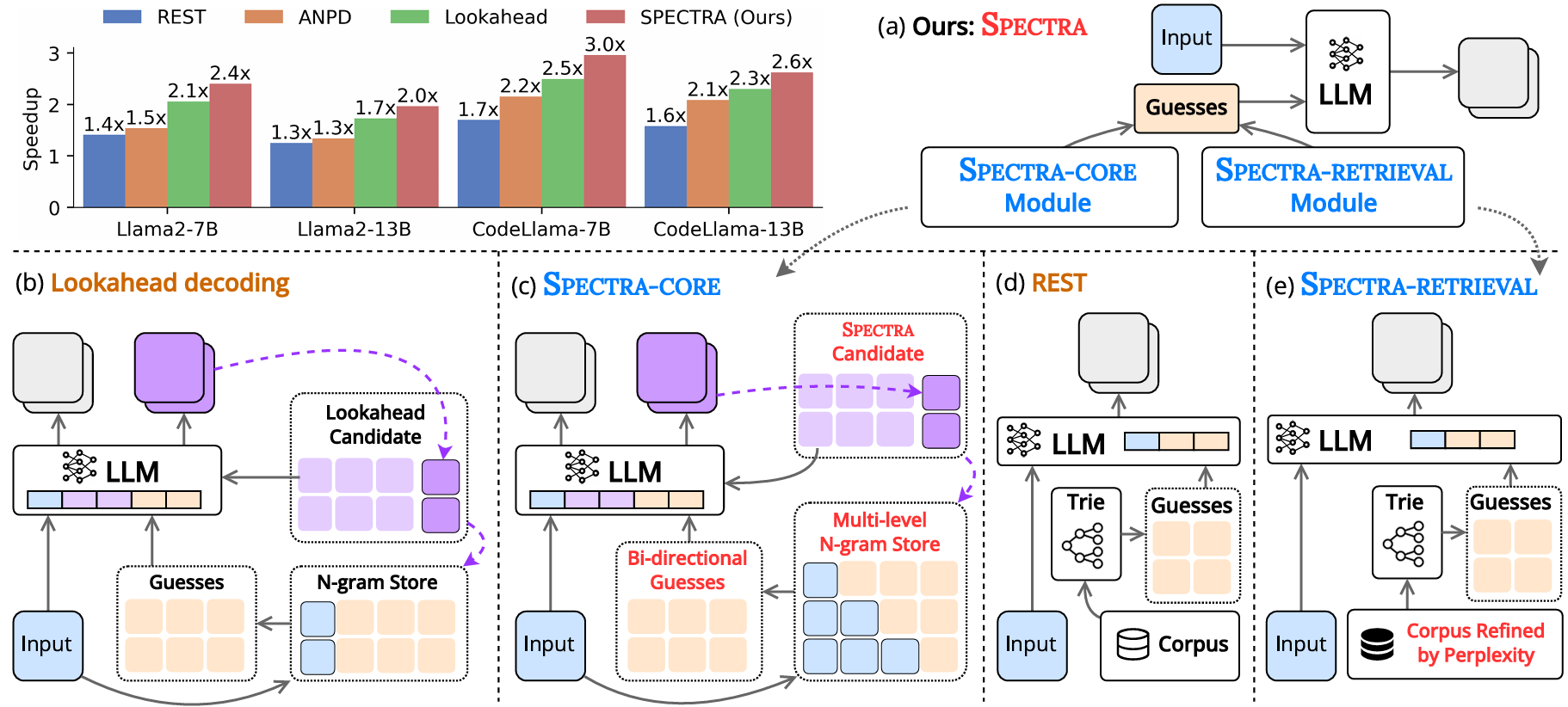
| 図1:SPECTRAの全体像と、他の学習不要なSOTA(最先端手法)との比較。 (a)SPECTRA(本研究)の概要。(b)Lookahead Decoding の概要。(c)SPECTRA-COREモジュールの概要:LLM内部の知識を活用して予測(guess)を生成。(d)REST の概要。(e)SPECTRA-RETRIEVALモジュールの概要:SPECTRA-COREと効率的に統合されるよう設計されており、高速化効果をさらに向上。 |
本研究は、国立研究開発法人科学技術振興機構(JST)次世代研究者挑戦的研究プログラム(SPRING)(JPMJSP2102)の支援のもとで行われました。
また、本研究成果は、2025年7月27日から8月1日にかけてオーストリアのウィーンで開催の、計算言語学及び自然言語処理の分野におけるにおけるトップカンファレンス「Association for Computational Linguistics(ACL2025)」で発表されました。
【論文情報】
| 題名 | SPECTRA: Faster Large Language Model Inference with Optimized Internal and External Speculation |
| 著者名 | Nguyen-Khang Le*, Dinh-Truong Do*, Nguyen Le Minh |
| 発表先 | Association for Computational Linguistics(ACL2025) |
| URL | https://aclanthology.org/2025.acl-long.685/ |
| DOI | 10.18653/v1/2025.acl-long.685 |
令和7年8月7日
